Beyond Static Checks: Designing CI/CD Pipelines That Respond to Live Security Signals
CI/CD pipelines miss runtime risk. Learn how to integrate real-time security signals into deployment decisions for safer, context-aware releases.
Join the DZone community and get the full member experience.
Join For FreeMost CI/CD pipelines are built around a simple idea: if your code passes tests and security scans before deployment, you’re good to go.
That used to be enough. It isn’t anymore.
Systems today are distributed, constantly changing, and exposed to real-time threats. A container image that looked perfectly safe during the build can become risky minutes later — because a node is compromised, a new vulnerability is discovered, or something suspicious starts running in the environment.
The problem is, pipelines don’t see any of that. They validate everything before deployment and then move forward blindly.
That’s the gap: we’re making release decisions without knowing the current security state of the system.
The Missing Signal in CI/CD
Most pipelines rely on three kinds of inputs:
- Code quality (unit and integration tests)
- Static security scans (SAST, SCA, image scanning)
- Deployment checks (smoke tests, health checks)
All of these are important. But they answer the same question, "Was this artifact safe when we built it?" They don’t answer the more important one, "Is it safe to deploy right now?"
Runtime environments introduce variables that static checks can’t capture — compromised hosts, unusual process activity, configuration drift, or newly detected threats. That’s exactly the kind of visibility platforms like CrowdStrike provide.
The issue is that the signal almost never makes it back into the deployment decision.
From Static Validation to Runtime-Aware Gating
To fix this, pipelines need to evolve. Instead of relying only on pre-deployment validation, they need to factor in live runtime risk.
That changes the model entirely:
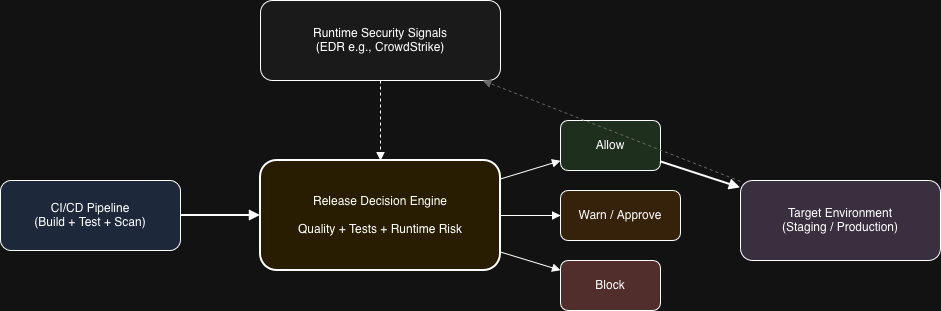
Release Decision = Code Quality + Test Results + Runtime Risk
Runtime risk comes from what’s happening right now in the environment:
- Active threat detections
- Behavioral anomalies
- Security posture signals
- Incidents affecting target systems
This doesn’t replace existing checks. It adds the missing layer of context.
A Practical Architecture
Here’s what a generalized approach looks like.
Signal Ingestion
Start by pulling runtime security signals from your EDR platform. That includes detections, severity levels, and affected assets. You’ll need to normalize that data into something your pipeline can understand and cache it to avoid slowing everything down.
Asset Correlation
This is where things get tricky.
You have to connect security signals to what you’re about to deploy. That means mapping workloads to nodes, nodes to hosts, and hosts to the signals coming from your security platform.
In environments built on Kubernetes, this usually involves labels, metadata, or some form of inventory mapping.
It’s not glamorous work, but without it, the rest doesn’t function.
Risk Scoring
Raw signals don’t help much on their own. You need to turn them into something actionable.
A simple model might look like this:
- No detections → low risk
- Medium severity alerts → moderate risk
- High severity active threats → high risk
You can refine it with time-based decay, confidence levels, or environment sensitivity. Production should be treated very differently from non-production.
Policy Decisions
Once you have a risk score, you need clear rules for what to do with it:
- Low risk → proceed
- Moderate risk → require approval
- High risk → block
This layer needs to be deterministic and auditable. Otherwise, people won’t trust it — and they’ll bypass it.
CI/CD Integration
Finally, plug this into your pipeline. Before deployment (or promotion between environments), the pipeline checks with the decision engine, "Is it safe to deploy right now?"
The answer isn’t just pass or fail anymore. It’s contextual.
How It Plays Out
A typical flow looks like this:
- Build completes and tests pass.
- Deployment is triggered.
- Runtime signals are pulled from the security platform.
- The system maps those signals to the target environment.
- A risk score is calculated.
- Policy rules are applied.
- The pipeline either proceeds, pauses for approval, or stops.
It’s the same pipeline — but now it’s aware of reality.
What You Need to Think Through
This isn’t free. There are real trade-offs.
Signal Freshness
If your data is stale, your decisions will be wrong.
You’ll need expiration rules, caching strategies, and a clear stance on what happens when data isn’t available — especially in production.
False Positives vs. Delivery Speed
If you block every deployment because of minor alerts, teams will lose trust quickly.
You need thresholds, exception paths, and a way to override decisions — with proper auditing.
Vendor Lock-In
Hard-coding your pipeline to a single tool is a mistake.
Design this as a pluggable system so you can swap or combine signal sources without reworking everything.
Latency
Pulling external signals during deployment can slow things down.
The usual workaround is pre-fetching data or maintaining a local cache of risk signals.
Failure Modes
You also need to decide what happens when things break:
- What if the security API is down?
- What if you can’t correlate assets?
- What if risk can’t be calculated?
Do you block everything, or allow deployments with warnings?
There’s no universal answer. It depends on how much risk your organization is willing to take.
Why This Matters
Teams already invest heavily in CI/CD, security scanning, and observability. But those systems often operate in silos.
The result is predictable:
- Deployments go into environments that aren’t actually safe
- Security signals are ignored until something breaks
- Incident response becomes reactive
Adding runtime awareness changes that.
You start making decisions based on what’s actually happening — not just what passed earlier checks.
The Bigger Shift
This isn’t just a pipeline tweak; it’s a shift in mindset. Instead of asking, "Did the build pas?" you start asking, "Is the system stable and safe enough to change right now?"
That shift leads to:
- Continuous risk evaluation
- Smarter deployment decisions
- Systems that adapt to real-world conditions
Closing Thoughts
CI/CD pipelines were designed for a world where validation happened before deployment. That world is gone. If deployments are going to stay fast, they also need to be aware of what’s happening in real time. Otherwise, speed just amplifies risk. Bringing runtime security signals into release decisions doesn’t slow you down — it keeps you from moving blindly. And at scale, that distinction matters more than anything.
Opinions expressed by DZone contributors are their own.
Comments