Conversational Risk Accumulation: Stateful Guardrails Beyond Single-Turn LLM Checks
Learn how Conversational Risk Accumulation (CRA) helps detect session-level risks in long AI chats using telemetry, drift tracking, and soft guardrails.
Join the DZone community and get the full member experience.
Join For FreeWhy Long Chats Need Session-Level Guardrails (CRA)
Who this is for: Anyone building chat features, support bots, internal Q&A, coaching tools, RAG assistants.
The Usual Setup (and What It Misses)
A typical flow:
- User sends a message.
- You run moderation, rules, or a small model on that message (sometimes the reply too).
- If it passes, the big model answers.
That is per message. It does not really “remember” the story of the chat.
In a long chat:
- Message 5 looks normal.
- Message 12 still passes your keyword list.
- By message 20, something is wrong only if you compare it to how the chat started.
So you can pass every single check and still end up with a bad session. That gap is what we call CRA: risk that adds up across turns, not in one obvious line.
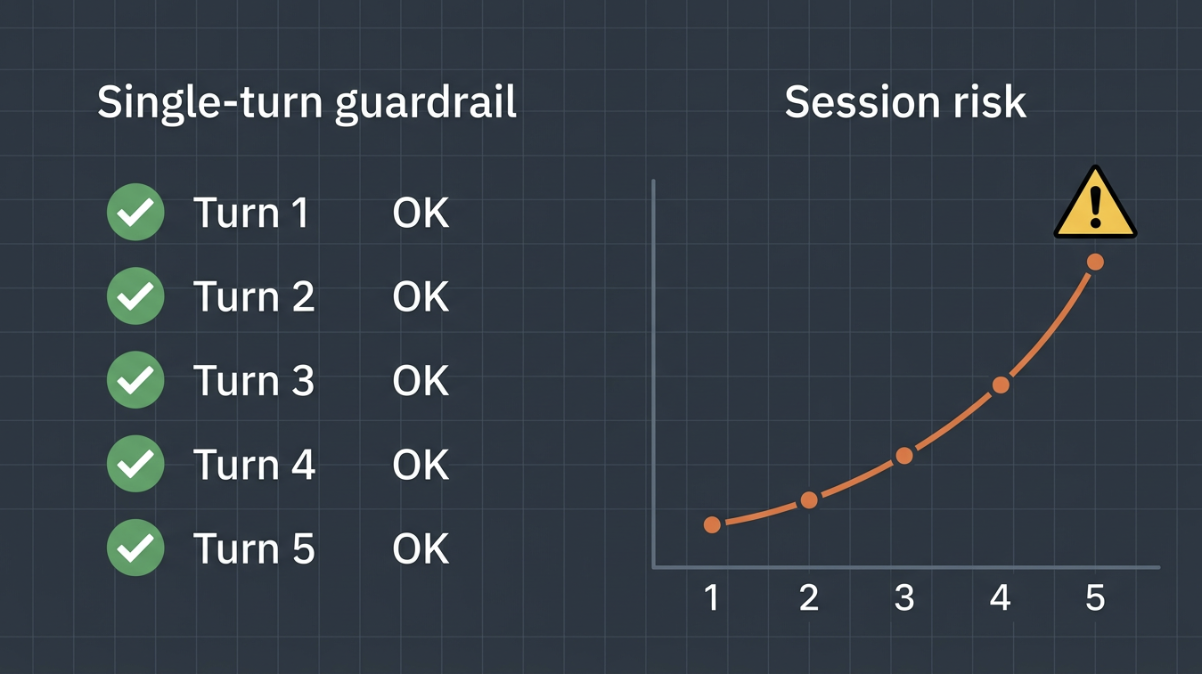
Figure 1: Each turn can look “green” while the overall thread is not.
CRA in Plain English
CRA = Conversational Risk Accumulation
Idea: Each turn might look okay on its own, but together they break the purpose of the chat or what your company is okay with.
What to build: Keep a little session memory (not the full transcript in logs — think IDs, hashes, and scores). After each assistant reply, update a few numbers that describe “how this session feels right now.”
Those numbers are hints for dashboards, alerts, and gentle UI — not a courtroom verdict.
Three Simple Scores + One Total (Example)
We use a small, fixed set of scores and one combined score. Version tag in code: cra_telemetry_v1.
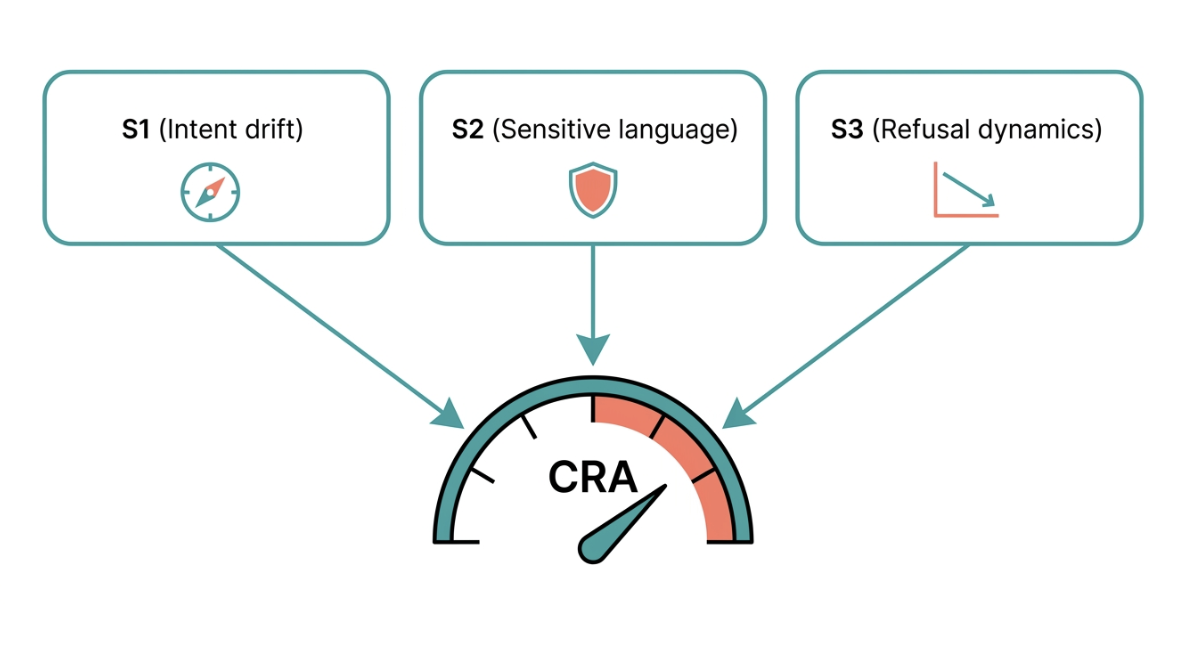
Figure 2: Three inputs, one combined CRA score.
| Score | Plain meaning | How you might compute it (conceptually) |
|---|---|---|
| S1 | Topic drift | Compare the user’s recent text to how the chat started (or a stated goal). If they wander far from that, S1 goes up. |
| S2 | Sensitive-looking replies | The assistant’s answer looks like it contains patterns you care about (fake email shapes, “API key” wording, etc.). This means “flag for review,” not “we proved a leak.” |
| S3 | Refusal tone shifting | Track refusal-style phrases in the assistant’s answers over time. If refusals seem to soften late in the thread, S3 captures that shape. |
| CRA | Overall session risk | A weighted sum of S1, S2, and S3, plus a small extra bump if the user or assistant text looks like prompt injection playbooks. Example weights we used: 35% S1, 45% S2, 20% S3. |
Rule of thumb: If you cannot explain a score in one short sentence to a product manager, do not use it to auto-block users.
Hard Guardrails = Simple, Fast, “No”
Hard guardrails are rules, not vibes. They should be cheap and run before you waste tokens.
Examples:
- Max request size – reject giant payloads (HTTP 413).
- Rate limits – cap requests per IP so one client cannot drain your budget (429).
- Known-bad phrases – block obvious “ignore all previous instructions” junk (400).
- “Don’t paste secrets” – block prompts that look like “here is my SSN” (400) with a clear error.
- Lock down outputs – if your product only allows certain actions, check model output and tool calls against an allowlist before anything runs.
These are not CRA. They are basics. CRA sits beside them.

Figure 3: Hard = block or validate. Soft = warn, log, nudge.
Soft Guardrails = CRA-Friendly, “Heads Up”
Soft means: warn, log, maybe show a banner — not silent blocking.
After a response, the API can add fields such as:
cra_soft_notices– short text for humans (“high drift”, “sensitive-looking wording”, …).cra_signals– numbers for debugging: S1, S2, S3, CRA, turn count.
Why start soft: Rules and heuristics misfire. A user might ask for fake email examples for a demo; S2 might spike on purpose. That is why the score is a signal, not proof.
Bonus: Cache Duplicate Questions (Save Money)
If someone double-clicks Send or retries the same text, do not call the model twice.
Cache key idea:
normalize(question) + mode + endpointCache the JSON answer for a few minutes. Mark responses with something like cached: true so the UI can say “from cache.”
Browser Tip: Don’t Mix Up “New Chat” and Old Intent
If S1 uses “first message of this session” as the anchor, browser storage can fool you: a new tab can look like a new thread while an old “first message” is still stored.
Fixes:
- Store the anchor per
session_id, not one global value. - Expire or rotate the browser session after idle time so deploys and stale tabs do not reuse the wrong anchor.
Telemetry vs. Guardrails (Two Different Jobs)
| Telemetry | Guardrail | |
|---|---|---|
| Job | Measure and learn | Block or change behavior |
| When it hurts you | Too many logs, privacy | False positives, angry users |
| CRA | Good fit | Use soft first; hard only after review |
In logs, avoid raw secrets. Prefer hashes, lengths, and labels (channel, product area).
Three Lines for Your Security Reviewer
- CRA is about conversation behavior over time, not a replacement for database security or tool-permission design.
- Labels for “bad session” are rare in the real world — use CRA to prioritize review, not as automatic guilt.
- If weights are public, people might game them — keep basic hard rules and spot checks anyway.
Rollout Order (Keep It Boring)
- Ship hard limits (size, rate, obvious injection, output checks).
- Add session logging with safe IDs.
- Show soft notices only inside internal tools first.
- Tune thresholds on real traffic.
- Only then add hard session actions (pause tools, re-auth, etc.).
Takeaway
One-message checks are not enough for long chats. CRA gives you a simple story and a small set of session scores. Hard rules stop obvious abuse; soft CRA helps you see drift before it becomes an incident.
Start with telemetry. Add blocking only when you understand the false positives.
About the author: Sanjay Mishra is author of two books, The SQL Universe and Oracle Database Performance Tuning: A Checklist Approach. His research spans RAG architectures, NL2SQL, LLM safety, and enterprise AI governance, with work published in IEEE Access, Springer LNNS, and SSRN. He speaks regularly at universities and industry events on applied AI and data engineering.
Tags / topics: #LLM #Security #Guardrails #Observability #OpenAI #Architecture #Chatbots
Opinions expressed by DZone contributors are their own.
Comments